
利用者:ぺお/sandbox
 |
ここはぺおさんの利用者サンドボックスです。編集を試したり下書きを置いておいたりするための場所であり、百科事典の記事ではありません。ただし、公開の場ですので、許諾されていない文章の転載はご遠慮ください。
登録利用者は自分用の利用者サンドボックスを作成できます(サンドボックスを作成する、解説)。 その他のサンドボックス: 共用サンドボックス | モジュールサンドボックス 記事がある程度できあがったら、編集方針を確認して、新規ページを作成しましょう。 |
実行時メモリオーダリング
[編集]SMPシステムの場合
[編集]- 逐次一貫性(すべての読み込みと書き込みは順番通りに実行される)
- 緩い一貫性(いくつかのリオーダリングが許される)
- 読み込みが他の読み込みの後に並び替えられる(キャッシュコヒーレンシやスケーラビリティのため)
- 読み込みが書き込みの後に並び替えられる
- 書き込みが他の書き込みの後に並び替えられる
- 書き込みが読み込みの後に並び替えられる
- 弱い一貫性(明示的なメモリバリアによる制限を除けば、読み込みと書き込みの任意の並び替えが可能)
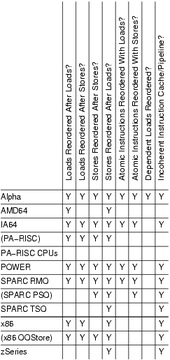
いくつかのCPUでは、
- 読み書き命令があると不可分操作がリオーダするかもしれない。
- 一貫性のない命令キャッシュパイプラインがありえる。 その場合、命令キャッシュのフラッシュ/再読み込みといった特殊な命令なしには自己書き換えコードが動かない。
- 依存関係のあるデータ読み込みもリオーダするかもしれない(Alpha固有)。プロセッサがあるデータへのポインタを読み込んだときでも、そのポインタが指す正しいデータではなく、すでにキャッシュされてまだ無効になっていない古いデータをフェッチするかもしれない。この緩いリオーダリングを許すことで、ハードウェアはシンプルで高速になるが、読み込み側と書き込み側の両方でメモリバリアが必要になる。[1]
Some older x86 and AMD systems have weaker memory ordering[4]
SPARC memory ordering modes:
- SPARC TSO = total store order (default)
- SPARC RMO = relaxed-memory order (not supported on recent CPUs)
- SPARC PSO = partial store order (not supported on recent CPUs)
Memory barrier types
[編集]Compiler memory barrier
[編集]These barriers prevent a compiler from reordering instructions, they do not prevent reordering by CPU.
- The GNU inline assembler statement
asm volatile("" ::: "memory");
or even
__asm__ __volatile__ ("" ::: "memory");
forbids GCC compiler to reorder read and write commands around it.[5]
- Intel ECC compiler uses "full compiler fence"
__memory_barrier()
- Microsoft Visual C++ Compiler:[8]
_ReadWriteBarrier()
Hardware memory barrier
[編集]Many architectures with SMP support have special hardware instruction for flushing reads and writes.
lfence (asm), void_mm_lfence(void) sfence (asm), void_mm_sfence(void)[9] mfence (asm), void_mm_mfence(void)[10]
sync (asm)
sync (asm)
mf (asm)
dcs (asm)
dmb (asm) dsb (asm) isb (asm)
Compiler support for hardware memory barriers
[編集]Some compilers support builtins that emit hardware memory barrier instructions:
- GCC,[12] version 4.4.0 and later,[13] has
__sync_synchronize. - The Microsoft Visual C++ compiler[14] has
MemoryBarrier(). - Sun Studio Compiler Suite[15] has
__machine_r_barrier,__machine_w_barrierand__machine_rw_barrier.
See also
[編集]References
[編集]- ^ Reordering on an Alpha processor by Kourosh Gharachorloo
- ^ Memory Ordering in Modern Microprocessors by Paul McKenney
- ^ Memory Barriers: a Hardware View for Software Hackers, Figure 5 on Page 16
- ^ Table 1. Summary of Memory Ordering, from "Memory Ordering in Modern Microprocessors, Part I"
- ^ GCC compiler-gcc.h
- ^ ECC compiler-intel.h
- ^ Intel(R) C++ Compiler Intrinsics Reference
Creates a barrier across which the compiler will not schedule any data access instruction. The compiler may allocate local data in registers across a memory barrier, but not global data.
- ^ Visual C++ Language Reference _ReadWriteBarrier
- ^ SFENCE — Store Fence
- ^ MFENCE — Memory Fence
- ^ Data Memory Barrier, Data Synchronization Barrier, and Instruction Synchronization Barrier.
- ^ Atomic Builtins
- ^ http://gcc.gnu.org/bugzilla/show_bug.cgi?id=36793
- ^ MemoryBarrier macro
- ^ Handling Memory Ordering in Multithreaded Applications with Oracle Solaris Studio 12 Update 2: Part 2, Memory Barriers and Memory Fence [1]
{kind=link}
Further reading
[編集]- Computer Architecture — A quantitative approach. 4th edition. J Hennessy, D Patterson, 2007. Chapter 4.6
- Sarita V. Adve, Kourosh Gharachorloo, Shared Memory Consistency Models: A Tutorial
- Intel 64 Architecture Memory Ordering White Paper
- Memory ordering in Modern Microprocessors part 1
- Memory ordering in Modern Microprocessors part 2
- IA (Intel Architecture) Memory Ordering - YouTube - Google Tech Talk